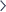
Česká transkripce japonštiny
Tento článek je věnovaný problematice spojené s českou transkripcí. Má cenu ji používat? K čemu je dobrá?
さぁぁぁぁ
FOTO: secretchina.com
Nejprve si povězme, co to vlastně transkripce je. Jedná se o přepis z jednoho písma do druhého (tedy v případě japonštiny se jedná o přepis katakany, hiragany a kandži do latinky). Zjednodušeně, transkripce tu je od toho, abyste to vy, jakožto čtenáři, dokázali přečíst.
A jaké jsou důvody, proč českou transkripci používat místo té anglické?
Zaprvé, dlouhé samohlásky. Japonská slova obsahují velmi mnoho dlouhých samohlásek (stejně jako česká) a přepis pomocí á, é, ú, ó, í je přesný, velice jednoduchý, pro Čechy přirozený a snadno srozumitelný. Pokud se chcete řídit revidovaným Hepburnovým přepisem, tak to správně přepíšete jako ā, ē, ī, ō, ū (nevím jak vy, ale já na své klávesnici tyhle znaky nemám…). Existuje ještě další varianta, jak přepisovat dlouhé samohlásky, a to â, ê, î, ô, û – jedná se o Kunrei šiki (standardizovaný přepis v Japonsku).
Kunrei šiki a Hepburn
Pro anglicky mluvící je samozřejmě nejvhodnější Hepburnový přepis, který bohužel není dodržovaný a přepis japonštiny do angličtiny se různě „prasí“. Můžeme si to kupříkladu ukázat na slově kókó (高校, střední škola). Ten Hepburnový by měl být „kōkō", ale s tím se na internetu moc nesetkáte. Spíše uvidíte přepis koko nebo koukou. Když už v češtině máme zápis pro dlouhé samohlásky, nevidím důvod, proč ho nevyužít.
Zadruhé, háčky. České hlásky s háčky odpovídají japonským hláskám (ve slabikách). Máme třeba slovo chijin (知人, známý). Jaká je pravděpodobnost, že člověk, který neumí anglicky, by to opravdu přečetl jako čidžin? Ze všech stran slýchávám, že v téhle době už umí anglicky každý. Ale já třeba ve svém okolí mám spoustu starších lidí, kteří anglicky neumějí vůbec, a dokonce ani někteří vrstevníci, ačkoliv se třeba anglicky učili, to nemusejí přečíst správně. Třeba takový můj otec by to bez okolků přečetl chyjin a nepřišlo by mu to v českém textu zvláštní.
Transkripce je tu tedy od toho, aby lidé, kteří nejsou rodilými mluvčími daného jazyka, byli schopní slovo či text přečíst. Navíc předpokládám, že naopak člověk, který angličtinu ovládá, tak si dá dvě a dvě dohromady a dojde mu, že čidžin se v anglické transkripci bude psát chijin. Co by ovšem nemusel vědět ani angličtinu ovládající čtenář je, jak přečíst zdvojené souhlásky. Například slovo 一緒 v Hepburnu přepíšeme jako issho a troufnu si tvrdit, že i angličtinář bez znalosti Hepburnu by nemusel vědět, že se to má přečíst iššo (jak příklad mohu uvést překlad knihy od Scotta Westerfelda, tuším že to byl Behemót – nebo jedna z knih té série – kde překladatel přepsal irasshaimasu jako irasšaimasu).
Alexandr Sergejevič Puškin
Jde tu o vztah japonština-čeština a ne japonština-angličtina-čeština. Je to podobný případ, jako kdybychom přepisovali ruské výrazy z azbuky do češtiny přes angličtinu, to bychom pak měli Alexander Sergeyevich Pushkin a ne Alexandr Sergejevič Puškin. Pro češtinu je prostě typické, že zápis a čtení jsou si docela podobné, a proto nevidím důvod, proč si to zbytečně ztěžovat používáním cizí transkripce – a proč zrovna té anglické, když existuje japonská (dokonce dvě!). Nebo můžeme jít do extrému a vyzkoušet ruskou – taky dobré, ne? Ostatně z toho vztahu tu pořád máme pozůstatek v podobě slova kamikadze.
Zatřetí, problém y/j. V Hepburnově přepisu se y čte jako j a j se čte jako dž. Pokud se takový přepis objeví v českém textu, tak čtenáři nemusí být hned jasné, že se to tak čte, a klidně to přečte špatně. Například jisho (辞書, slovník) přečte jako jišo (v horším případě jako jisho) a nemusí ho napadnout, že je to džišo.

Slovník
Další argumenty proti české transkripci. Setkala jsem se například s takovým, že angličtinu přece taky nepřepisujeme, tak proč by Mayu, která je tak „všude po internetu“, měla být psaná Maju. Ano, angličtinu nepřepisujeme a zřejmě ani nikdy nebudeme. Ale angličtina má jednu velikou výhodu oproti japonštině – zapisuje se v latince. Japonština však latinku nepoužívá, a tak nezbývá než to přepsat. A když už to tedy musíme přepsat a ještě navíc máme na výběr jak to přepsat, tak proč nevyužít češtiny, když se nabízí?
Setkala jsem se taktéž s argumentem: „Kdybych to viděl napsaný jako cunami, musel bych dlouho přemýšlet, co to znamená.“ To má člověk chuť se zeptat, jestli když se dotyčný setká se slovem tsunami, tak to čte jako t-sunami nebo jak, protože nevím jak kdo, ale já když vidím tsunami, čtu to kupodivu cunami (protože umím anglicky, můj taťka to jako t-sunami čte). K tomu se vztahuje i reklama, kterou mělo Makro na wagyu (japonské hovězí). Táta se mě rafinovaně ptal, co je to to wagiu, že když už se učím japonsky, tak bych to přece měla vědět… a druhým dechem dodával, proč je to wagiu tak pojmenované, jestli to není proto, že je to maso z… Každopádně, správný český přepis by byl wagjú.

Makro a wagyu
Dalším argumentem bývá, že se s českou transkripcí nedá komunikovat se světem (tj. s anglicky mluvícím světem). Ovšem tady se to opět stáčí k tomu, že angličtinář by měl mít schopnost rozpoznat v českém dži anglické ji apod. Tedy v případě, že se zahraničím komunikujete anglicky (což by se dalo předpokládat).
A nakonec je to prostě o vzhledu. Zastáncům anglického přepisu se prostě nelíbí, když jim jejich milovaná slova przníme háčky a čárkami a podobnými zvrhlostmi. Jenomže ať se jim to líbí nebo ne, Džiraija (自来也) se bude vždycky číst Džiraija nebo Japonec vždy přečte jméno 松本潤 zpěváka ze skupiny Araši Macumoto Džun a ne jinak.

Kulič Džiraija
Pár ukázek přepisů
Máme jméno 大野智
Český přepis: Óno Satoši
Hepburn: Ōno Satoshi
Japonský přepis (Nihon šiki): Ôno Satosi
Je možné ještě na internetu najít za různá znění příjmení*: Ono, Ohno, Oono (= wápuro°)
Kupodivu je nejrozšířenější přepis Ohno a je asi jasné, jak to minimálně neangličtináři čtou…
Podobné problémy jsou například i u „anglického“ přepisu příjmení Sató – správné je Satō, najdeme to ale jako Sato, Satou (= wápuro°) případně Satoh.
Pro srovnání třeba přepis slabik „ou“
孔子(こうし) – Konfucius
Česká transkripce: Kóši
Hepburn: Kōshi
Japonský přepis: Kôshi
Internet*: Koshi, Koushi (= wápuro°)
VS
小牛(こうし) – tele
Česká transkripce: kouši
Hepburn: koushi (taktéž i japonský přepis)
Internet*: koushi (= wápuro°)
Ano, není hrozná chyba, kvůli které by se zbortil svět, ale tak chceme být co nejpřesnější, ne?
Netvrdím, že česká transkripce je nejlepší na světě, pojďme ji okamžitě používat! Používejte si transkripci, jakou chcete, ale používejte ji alespoň správně a jednotně. A, ano, vyžaduje to trochu snahy a ne jen bezduše kopírovat jména a dál se tím nezabývat. To platí jak pro tu českou, tak i pro správně použitou Hepburnovu transkripci. Ale jak do toho jednou proniknete, jde to pak snadno a navíc se najde vždy někdo ochotný, kdo by vám poradil, jak co přepsat do transkripce, kterou chcete používat.
Samozřejmě je ze začátku těžké přeorientovat se na transkripci, kde se najednou místo Shingeki no kyojin píše Šingeki no kjodžin, ale vše je to jen o zvyku. A minimálně byste měli pochopit, že pokud v českých překladech a českých textech je česká transkripce, tak to není důvod to hned nenávidět a psát, že je to špatně přepsané a hnusné a vůbec. Anglický přepis, na který je většina fandomu zvyklá, je vhodný pro anglické prostředí, nikoliv pro to české, a proto je logické, že u nás bude použita v knihách, časopisech, médiích atd. česká transkripce. Sama mám občas potíže něco, co často vídávám na anglických webech, napsat v české transkripci, ale když už píši text v češtině anebo do češtiny překládám, přijde mi přirozené, logické a správné ji použít.
* = co můžeme najít na internetu a co tváří se to jako anglická transkripce, ačkoliv je to většinou jen nepovedený pokus o přepis
° = při zadávání do počítače

Česká transkripce
ZDROJE: wikipedia, kavarnistka.blogspot.cz (pro více informací o tématu sem určitě zajděte, mnoho myšlenek jsem si od slečny vypůjčila, neboť s nimi souhlasím a mám podobné zážitky) a inspirovala jsem se u hintza.
FOTO: kawayasu2.blog80.fc2, mujweb, ceskatelevize, kufs.ac.jp, makro,
A jaké jsou důvody, proč českou transkripci používat místo té anglické?
Zaprvé, dlouhé samohlásky. Japonská slova obsahují velmi mnoho dlouhých samohlásek (stejně jako česká) a přepis pomocí á, é, ú, ó, í je přesný, velice jednoduchý, pro Čechy přirozený a snadno srozumitelný. Pokud se chcete řídit revidovaným Hepburnovým přepisem, tak to správně přepíšete jako ā, ē, ī, ō, ū (nevím jak vy, ale já na své klávesnici tyhle znaky nemám…). Existuje ještě další varianta, jak přepisovat dlouhé samohlásky, a to â, ê, î, ô, û – jedná se o Kunrei šiki (standardizovaný přepis v Japonsku).
Kunrei šiki a Hepburn
Pro anglicky mluvící je samozřejmě nejvhodnější Hepburnový přepis, který bohužel není dodržovaný a přepis japonštiny do angličtiny se různě „prasí“. Můžeme si to kupříkladu ukázat na slově kókó (高校, střední škola). Ten Hepburnový by měl být „kōkō", ale s tím se na internetu moc nesetkáte. Spíše uvidíte přepis koko nebo koukou. Když už v češtině máme zápis pro dlouhé samohlásky, nevidím důvod, proč ho nevyužít.
Zadruhé, háčky. České hlásky s háčky odpovídají japonským hláskám (ve slabikách). Máme třeba slovo chijin (知人, známý). Jaká je pravděpodobnost, že člověk, který neumí anglicky, by to opravdu přečetl jako čidžin? Ze všech stran slýchávám, že v téhle době už umí anglicky každý. Ale já třeba ve svém okolí mám spoustu starších lidí, kteří anglicky neumějí vůbec, a dokonce ani někteří vrstevníci, ačkoliv se třeba anglicky učili, to nemusejí přečíst správně. Třeba takový můj otec by to bez okolků přečetl chyjin a nepřišlo by mu to v českém textu zvláštní.
Transkripce je tu tedy od toho, aby lidé, kteří nejsou rodilými mluvčími daného jazyka, byli schopní slovo či text přečíst. Navíc předpokládám, že naopak člověk, který angličtinu ovládá, tak si dá dvě a dvě dohromady a dojde mu, že čidžin se v anglické transkripci bude psát chijin. Co by ovšem nemusel vědět ani angličtinu ovládající čtenář je, jak přečíst zdvojené souhlásky. Například slovo 一緒 v Hepburnu přepíšeme jako issho a troufnu si tvrdit, že i angličtinář bez znalosti Hepburnu by nemusel vědět, že se to má přečíst iššo (jak příklad mohu uvést překlad knihy od Scotta Westerfelda, tuším že to byl Behemót – nebo jedna z knih té série – kde překladatel přepsal irasshaimasu jako irasšaimasu).
Alexandr Sergejevič Puškin
Jde tu o vztah japonština-čeština a ne japonština-angličtina-čeština. Je to podobný případ, jako kdybychom přepisovali ruské výrazy z azbuky do češtiny přes angličtinu, to bychom pak měli Alexander Sergeyevich Pushkin a ne Alexandr Sergejevič Puškin. Pro češtinu je prostě typické, že zápis a čtení jsou si docela podobné, a proto nevidím důvod, proč si to zbytečně ztěžovat používáním cizí transkripce – a proč zrovna té anglické, když existuje japonská (dokonce dvě!). Nebo můžeme jít do extrému a vyzkoušet ruskou – taky dobré, ne? Ostatně z toho vztahu tu pořád máme pozůstatek v podobě slova kamikadze.
Zatřetí, problém y/j. V Hepburnově přepisu se y čte jako j a j se čte jako dž. Pokud se takový přepis objeví v českém textu, tak čtenáři nemusí být hned jasné, že se to tak čte, a klidně to přečte špatně. Například jisho (辞書, slovník) přečte jako jišo (v horším případě jako jisho) a nemusí ho napadnout, že je to džišo.
Slovník
Další argumenty proti české transkripci. Setkala jsem se například s takovým, že angličtinu přece taky nepřepisujeme, tak proč by Mayu, která je tak „všude po internetu“, měla být psaná Maju. Ano, angličtinu nepřepisujeme a zřejmě ani nikdy nebudeme. Ale angličtina má jednu velikou výhodu oproti japonštině – zapisuje se v latince. Japonština však latinku nepoužívá, a tak nezbývá než to přepsat. A když už to tedy musíme přepsat a ještě navíc máme na výběr jak to přepsat, tak proč nevyužít češtiny, když se nabízí?
Setkala jsem se taktéž s argumentem: „Kdybych to viděl napsaný jako cunami, musel bych dlouho přemýšlet, co to znamená.“ To má člověk chuť se zeptat, jestli když se dotyčný setká se slovem tsunami, tak to čte jako t-sunami nebo jak, protože nevím jak kdo, ale já když vidím tsunami, čtu to kupodivu cunami (protože umím anglicky, můj taťka to jako t-sunami čte). K tomu se vztahuje i reklama, kterou mělo Makro na wagyu (japonské hovězí). Táta se mě rafinovaně ptal, co je to to wagiu, že když už se učím japonsky, tak bych to přece měla vědět… a druhým dechem dodával, proč je to wagiu tak pojmenované, jestli to není proto, že je to maso z… Každopádně, správný český přepis by byl wagjú.
Makro a wagyu
Dalším argumentem bývá, že se s českou transkripcí nedá komunikovat se světem (tj. s anglicky mluvícím světem). Ovšem tady se to opět stáčí k tomu, že angličtinář by měl mít schopnost rozpoznat v českém dži anglické ji apod. Tedy v případě, že se zahraničím komunikujete anglicky (což by se dalo předpokládat).
A nakonec je to prostě o vzhledu. Zastáncům anglického přepisu se prostě nelíbí, když jim jejich milovaná slova przníme háčky a čárkami a podobnými zvrhlostmi. Jenomže ať se jim to líbí nebo ne, Džiraija (自来也) se bude vždycky číst Džiraija nebo Japonec vždy přečte jméno 松本潤 zpěváka ze skupiny Araši Macumoto Džun a ne jinak.
Kulič Džiraija
Pár ukázek přepisů
Máme jméno 大野智
Český přepis: Óno Satoši
Hepburn: Ōno Satoshi
Japonský přepis (Nihon šiki): Ôno Satosi
Je možné ještě na internetu najít za různá znění příjmení*: Ono, Ohno, Oono (= wápuro°)
Kupodivu je nejrozšířenější přepis Ohno a je asi jasné, jak to minimálně neangličtináři čtou…
Podobné problémy jsou například i u „anglického“ přepisu příjmení Sató – správné je Satō, najdeme to ale jako Sato, Satou (= wápuro°) případně Satoh.
Pro srovnání třeba přepis slabik „ou“
孔子(こうし) – Konfucius
Česká transkripce: Kóši
Hepburn: Kōshi
Japonský přepis: Kôshi
Internet*: Koshi, Koushi (= wápuro°)
VS
小牛(こうし) – tele
Česká transkripce: kouši
Hepburn: koushi (taktéž i japonský přepis)
Internet*: koushi (= wápuro°)
Ano, není hrozná chyba, kvůli které by se zbortil svět, ale tak chceme být co nejpřesnější, ne?
Netvrdím, že česká transkripce je nejlepší na světě, pojďme ji okamžitě používat! Používejte si transkripci, jakou chcete, ale používejte ji alespoň správně a jednotně. A, ano, vyžaduje to trochu snahy a ne jen bezduše kopírovat jména a dál se tím nezabývat. To platí jak pro tu českou, tak i pro správně použitou Hepburnovu transkripci. Ale jak do toho jednou proniknete, jde to pak snadno a navíc se najde vždy někdo ochotný, kdo by vám poradil, jak co přepsat do transkripce, kterou chcete používat.
Samozřejmě je ze začátku těžké přeorientovat se na transkripci, kde se najednou místo Shingeki no kyojin píše Šingeki no kjodžin, ale vše je to jen o zvyku. A minimálně byste měli pochopit, že pokud v českých překladech a českých textech je česká transkripce, tak to není důvod to hned nenávidět a psát, že je to špatně přepsané a hnusné a vůbec. Anglický přepis, na který je většina fandomu zvyklá, je vhodný pro anglické prostředí, nikoliv pro to české, a proto je logické, že u nás bude použita v knihách, časopisech, médiích atd. česká transkripce. Sama mám občas potíže něco, co často vídávám na anglických webech, napsat v české transkripci, ale když už píši text v češtině anebo do češtiny překládám, přijde mi přirozené, logické a správné ji použít.
* = co můžeme najít na internetu a co tváří se to jako anglická transkripce, ačkoliv je to většinou jen nepovedený pokus o přepis
° = při zadávání do počítače
Česká transkripce
ZDROJE: wikipedia, kavarnistka.blogspot.cz (pro více informací o tématu sem určitě zajděte, mnoho myšlenek jsem si od slečny vypůjčila, neboť s nimi souhlasím a mám podobné zážitky) a inspirovala jsem se u hintza.
FOTO: kawayasu2.blog80.fc2, mujweb, ceskatelevize, kufs.ac.jp, makro,



Nástěnka
09:31 |
30.01
jameswick1...
 skoro po dvou letech si zas dovolím jeden spam pří...
skoro po dvou letech si zas dovolím jeden spam pří...
10:39 |
10.01
8BB76E1
 Japonské slavnosti na Vyšehradě 8.6.2019 - relativ...
Japonské slavnosti na Vyšehradě 8.6.2019 - relativ...
19:53 |
08.06
Tyckin
TOP0 článků
Poslední komentáře








{kind=link}
